Quartus II/ ModelSim을 이용한 구현 - 3. CLA(Carry Look-ahead Adder) (verilog)
2023. 1. 28. 16:11ㆍ기록지/컴퓨터구조(computer architecture)
Carry Look-ahead Adder 구현
원리
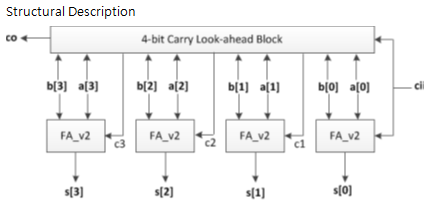
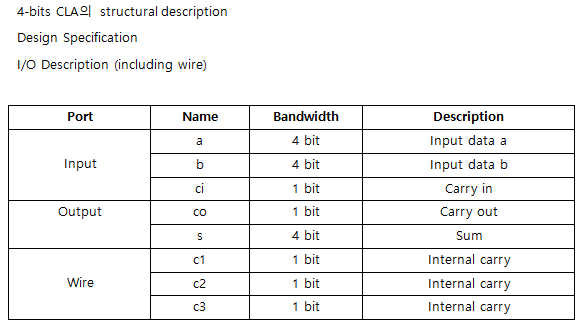
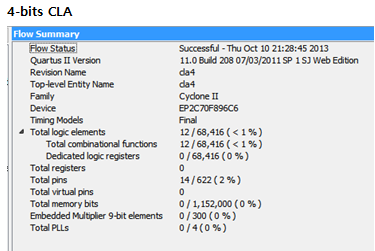
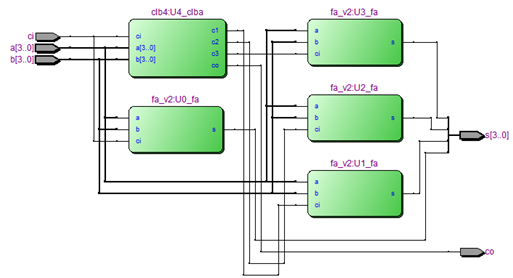
4-bits Carry Look-ahead Adder
Ripple carry adder (RCA)가 계산이 완료 될 때까지 시간이 많이 걸리는 단점을 보완하기 위해 입력 a, b 그리고 carry in이 주어질 때, 모든 올림수가 동시에 구해져 계산시간을 단축시키는 가산기이다. Carry를 계산하기 위해 carry만을 계산해주는 별도의 carry look-ahead block이 존재한다.

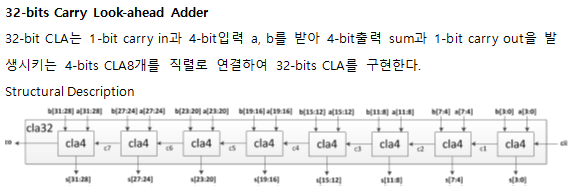
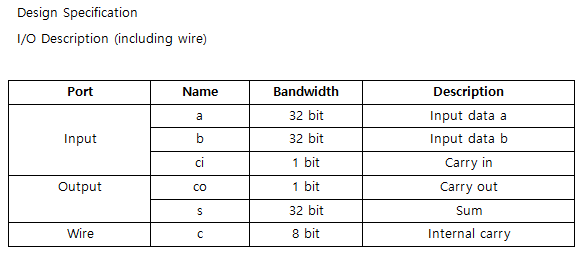
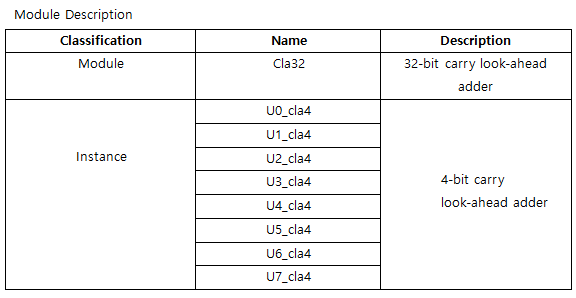
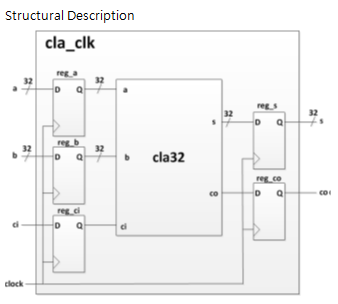
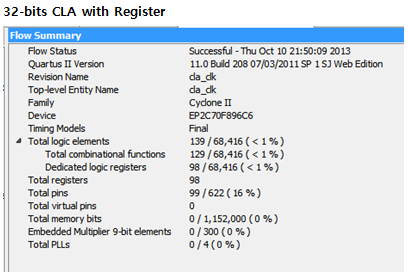
32-bits CLA with clock
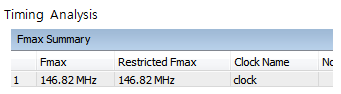
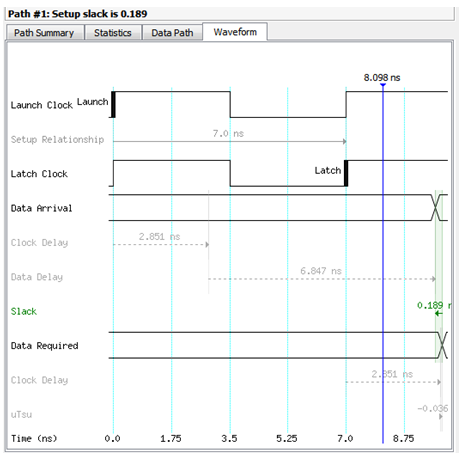
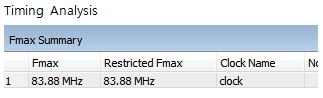
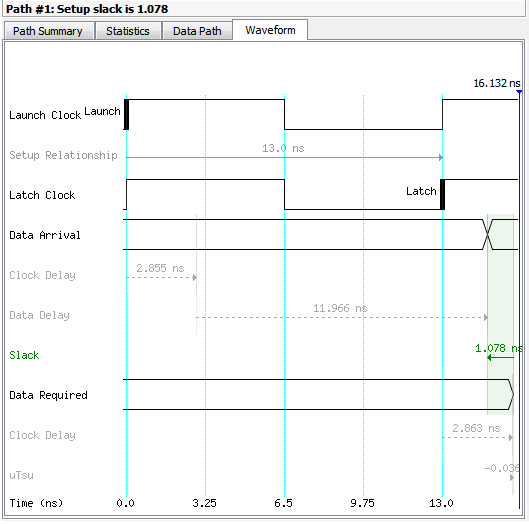
Timing Analysis
구현한 logic이 제대로 동작할 수 있는 조건을 찾기 위하여 해당 circuit의 delay를 분석하는 과정이다. 일반적으로 여기서 찾는 조건은 최대 동작 주파수이다.
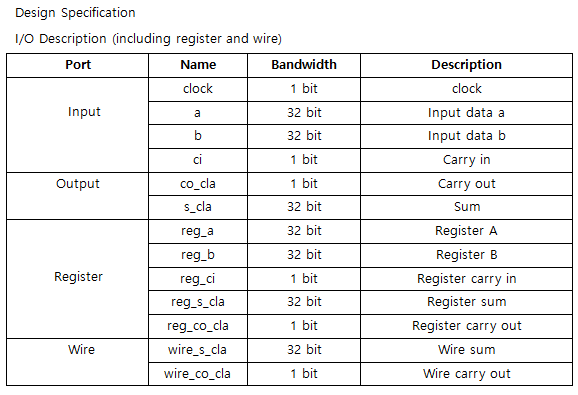

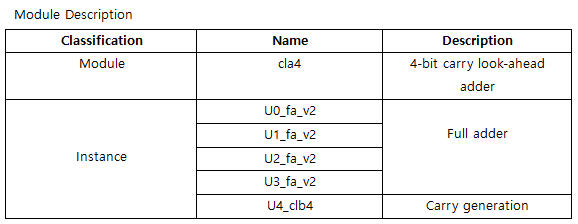
설계 검증
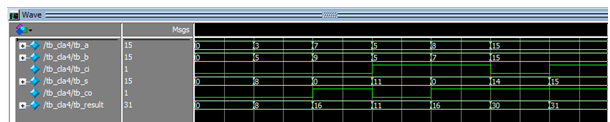

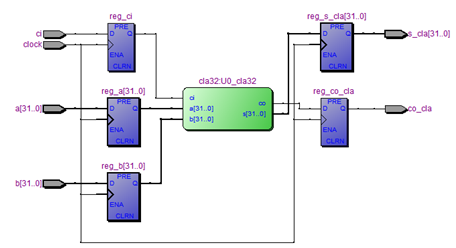
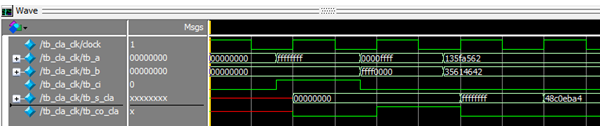

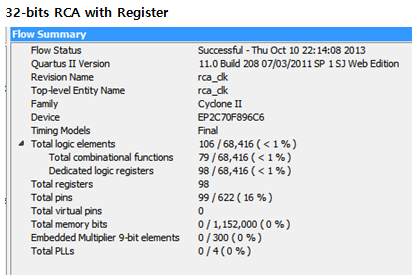
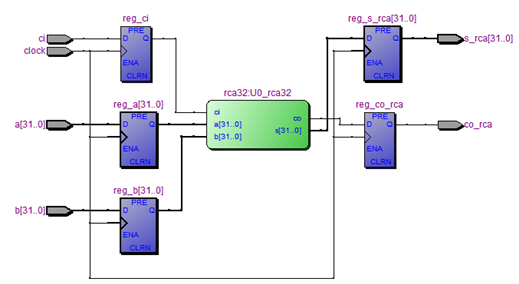
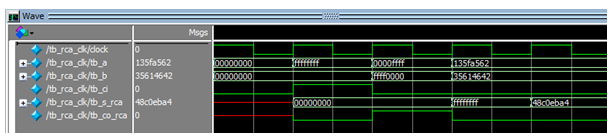
Input값이 5ns delay 되었을 뿐 모든 결과 값은 32-bits CLA wave form과 일치한다.
module cla4(a,b,ci,s,co);
input [3:0] a,b;
input ci;
output [3:0] s;
output co;
wire c1,c2,c3;
fa_v2 U0_fa (.a(a[0]),.b(b[0]),.ci(ci),.s(s[0]));
fa_v2 U1_fa (.a(a[1]),.b(b[1]),.ci(c1),.s(s[1]));
fa_v2 U2_fa (.a(a[2]),.b(b[2]),.ci(c2),.s(s[2]));
fa_v2 U3_fa (.a(a[3]),.b(b[3]),.ci(c3),.s(s[3]));
clb4 U4_clba (.a(a),.b(b),.ci(ci),.c1(c1),.c2(c2),.c3(c3),.co(co));
endmodule
module clb4(a,b,ci,c1,c2,c3,co);
input [3:0] a,b;
input ci;
output c1,c2,c3,co;
wire[3:0] g, p; //generate, propagate
wire w0_c1;
wire w0_c2, w1_c2;
wire w0_c3, w1_c3, w2_c3;
wire w0_co, w1_co, w2,co, w3_co;
//Generate
_and2 U0_and2 (.a(a[0]),.b(b[0]),.y(g[0]));
_and2 U1_and2 (.a(a[1]),.b(b[1]),.y(g[1]));
_and2 U2_and2 (.a(a[2]),.b(b[2]),.y(g[2]));
_and2 U3_and2 (.a(a[3]),.b(b[3]),.y(g[3]));
//Propagate
_or2 U4_or2 (.a(a[0]),.b(b[0]),.y(p[0]));
_or2 U5_or2 (.a(a[1]),.b(b[1]),.y(p[1]));
_or2 U6_or2 (.a(a[2]),.b(b[2]),.y(p[2]));
_or2 U7_or2 (.a(a[3]),.b(b[3]),.y(p[3]));
//c1= g[0] | (p[0] & ci);
_and2 U8_and2 (.a(p[0]),.b(ci),.y(w0_c1));
_or2 U9_or2 (.a(g[0]),.b(w0_c1),.y(c1));
//c2= g[1]
// | (p[1] & g[0])
// | (p[1] & p[0] & ci);
_and2 U10_and2 (.a(p[1]),.b(g[0]),.y(w0_c2));
_and3 U11_and3 (.a(p[1]),.b(p[0]),.c(ci),.y(w1_c2));
_or3 U12_or3 (.a(g[1]),.b(w0_c2),.c(w1_c2),.y(c2));
//c3= g[2]
// | (p[2] & g[1])
// | (p[2] & p[1] & g[0])
// | (p[2] & p[1] & p[0] & ci);
_and2 U13_and2 (.a(p[2]),.b(g[1]),.y(w0_c3));
_and3 U14_and3 (.a(p[2]),.b(p[1]),.c(g[0]),.y(w1_c3));
_and4 U15_and4 (.a(p[2]),.b(p[1]),.c(p[0]),.d(ci),.y(w2_c3));
_or4 U16_or4 (.a(g[2]),.b(w0_c3),.c(w1_c3),.d(w2_c3),.y(c3));
//co= g[3]
// | (p[3] & g[2])
// | (p[3] & p[2] & g[1])
// | (p[3] & p[2] & p[1] & g[0])
// | (p[3] & p[2] & p[1] & p[0] & ci);
_and2 U17_and2 (.a(p[3]),.b(g[2]),.y(w0_co));
_and3 U18_and3 (.a(p[3]),.b(p[2]),.c(g[1]),.y(w1_co));
_and4 U19_and4 (.a(p[3]),.b(p[2]),.c(p[1]),.d(g[0]),.y(w2_co));
_and5 U20_and5 (.a(p[3]),.b(p[2]),.c(p[1]),.d(p[0]),.e(ci),.y(w3_co));
_or5 U21_or5 (.a(g[3]),.b(w0_co),.c(w1_co),.d(w2_co),.e(w3_co),.y(co));
endmodule
module fa_v2(a,b,ci,s);
input a,b,ci;
output s;
wire w;
_xor2 U0_Xor2(.a(a),.b(b),.y(w));
_xor2 U1_Xor2(.a(w),.b(ci),.y(s));
endmodule
module _inv(a,y);
input a;
output y;
assign y=~a;
endmodule
module _nand2(a,b,y);
input a,b;
output y;
assign y=~(a&b);
endmodule
module _and2(a,b,y);
input a,b;
output y;
assign y=a&b;
endmodule
module _or2(a,b,y);
input a,b;
output y;
assign y=a|b;
endmodule
module _xor2(a,b,y);
input a,b;
output y;
wire w1,w2,w3,w4;
_inv _inv0(.a(a),.y(w1));
_inv _inv1(.a(b),.y(w2));
_and2 _and0(.a(a),.b(w2),.y(w3));
_and2 _and1(.a(b),.b(w1),.y(w4));
_or2 _or0(.a(w3),.b(w4),.y(y));
endmodule
module _and3(a,b,c,y);
input a,b,c;
output y;
assign y=a&b&c;
endmodule
module _and4(a,b,c,d,y);
input a,b,c,d;
output y;
assign y=a&b&c&d;
endmodule
module _and5(a,b,c,d,e,y);
input a,b,c,d,e;
output y;
assign y=a&b&c&d&e;
endmodule
module _or3(a,b,c,y);
input a,b,c;
output y;
assign y=a|b|c;
endmodule
module _or4(a,b,c,d,y);
input a,b,c,d;
output y;
assign y=a|b|c|d;
endmodule
module _or5(a,b,c,d,e,y);
input a,b,c,d,e;
output y;
assign y=a|b|c|d|e;
endmodule
`timescale 1ns/100ps
module tb_cla4;
reg [3:0] tb_a, tb_b;
reg tb_ci;
wire [3:0] tb_s;
wire tb_co;
wire [4:0] tb_result;
assign tb_result= {tb_co,tb_s};
cla4 U0_cla4(.a(tb_a),.b(tb_b),.ci(tb_ci),.s(tb_s),.co(tb_co));
initial
begin
tb_ci=0;tb_a=0;tb_b=0;
#10; tb_a=4'h3; tb_b=4'h5; tb_ci=0;
#10; tb_a=4'h7; tb_b=4'h9; tb_ci=0;
#10; tb_a=4'h5; tb_b=4'h5; tb_ci=1;
#10; tb_a=4'h8; tb_b=4'h7; tb_ci=1;
#10; tb_a=4'hf; tb_b=4'hf; tb_ci=0;
#10; tb_a=4'hf; tb_b=4'hf; tb_ci=1;
#10; $stop;
end
endmodule
module cla32(a,b,ci,s,co);
input [31:0] a,b;
input ci;
output [31:0] s;
output co;
wire c1,c2,c3,c4,c5,c6,c7;
cla4 U0_cla4(.a(a[3:0]),.b(b[3:0]),.ci(ci),.s(s[3:0]),.co(c1));
cla4 U1_cla4(.a(a[7:4]),.b(b[7:4]),.ci(c1),.s(s[7:4]),.co(c2));
cla4 U2_cla4(.a(a[11:8]),.b(b[11:8]),.ci(c2),.s(s[11:8]),.co(c3));
cla4 U3_cla4(.a(a[15:12]),.b(b[15:12]),.ci(c3),.s(s[15:12]),.co(c4));
cla4 U4_cla4(.a(a[19:16]),.b(b[19:16]),.ci(c4),.s(s[19:16]),.co(c5));
cla4 U5_cla4(.a(a[23:20]),.b(b[23:20]),.ci(c5),.s(s[23:20]),.co(c6));
cla4 U6_cla4(.a(a[27:24]),.b(b[27:24]),.ci(c6),.s(s[27:24]),.co(c7));
cla4 U7_cla4(.a(a[31:28]),.b(b[31:28]),.ci(c7),.s(s[31:28]),.co(co));
endmodule
`timescale 1ns/100ps
module tb_cla_clk;
reg clock;
reg [31:0] tb_a, tb_b;
reg tb_ci;
wire [31:0] tb_s_cla;
wire tb_co_cla;
parameter STEP =10;
cla_clk U0_cla_clk(.clock(clock),.a(tb_a),.b(tb_b),.ci(tb_ci),.s_cla(tb_s_cla),.co_cla(tb_co_cla));
always#(STEP/2) clock = ~clock;
initial
begin
clock=1'b1; tb_a=32'h0; tb_b=32'h0; tb_ci=1'b0;
#(STEP-2); tb_a=32'hffff_ffff; tb_b=32'h0; tb_ci=1'b1;
#(STEP); tb_a=32'h0000_ffff; tb_b=32'hffff_0000; tb_ci=1'b0;
#(STEP); tb_a=32'h135f_a562; tb_b=32'h3561_4642; tb_ci=1'b0;
#(STEP*2); $stop;
end
endmodule
module cla_clk(clock, a,b,ci,s_cla,co_cla);
input clock;
input [31:0] a,b;
input ci;
output [31:0] s_cla;
output co_cla;
reg [31:0] reg_a, reg_b;
reg reg_ci;
reg [31:0] reg_s_cla;
reg reg_co_cla;
wire [31:0] wire_s_cla;
wire wire_co_cla;
always @ (posedge clock)
begin
reg_a <= a;
reg_b <= b;
reg_ci <= ci;
reg_s_cla <= wire_s_cla;
reg_co_cla <= wire_co_cla;
end
cla32 U0_cla32 (.a(reg_a),.b(reg_b),.ci(reg_ci),.s(wire_s_cla),.co(wire_co_cla));
assign s_cla = reg_s_cla;
assign co_cla = reg_co_cla;
endmodule
module fa(a,b,ci,s,co); // full adder
input a,b,ci; // input
output s,co; // output
wire sm,c1,c2; // wire
//named mapping
ha U0_ha(.a(b),.b(ci),.s(sm),.co(c1)); // instance of ha
ha U1_ha(.a(a),.b(sm),.s(s),.co(c2)); // instance of ha
_or2 U0_or(.a(c2),.b(c1),.y(co)); //instance of _or2
endmodule
module ha(a,b,s,co); // half adder
input a,b; // input
output s,co; // output
//named mapping
_and2 _and0(.a(a),.b(b),.y(co)); // instance of _and2
_xor2 _xor0(.a(a),.b(b),.y(s)); //instance of _xor2
endmodule
module rca(a,b,ci,s,co); // ripple carry adder
input [3:0] a,b; // 4bit input
input ci;
output [3:0] s; // 4bit output
output co;
wire [2:0]c; // 3bit wire
//named mapping
fa U0_fa(.a(a[0]),.b(b[0]),.ci(ci),.s(s[0]),.co(c[0])); // instance of fa
fa U1_fa(.a(a[1]),.b(b[1]),.ci(c[0]),.s(s[1]),.co(c[1]));
fa U2_fa(.a(a[2]),.b(b[2]),.ci(c[1]),.s(s[2]),.co(c[2]));
fa U3_fa(.a(a[3]),.b(b[3]),.ci(c[2]),.s(s[3]),.co(co));
endmodule728x90
'기록지 > 컴퓨터구조(computer architecture)' 카테고리의 다른 글
| Quartus II/ ModelSim을 이용한 구현 - 5. Latch, Flip-Flop (0) | 2023.01.30 |
|---|---|
| Quartus II/ ModelSim을 이용한 구현 - 4. ALU(Arithmetic Logic Unit), Substractor (0) | 2023.01.29 |
| Quartus II/ ModelSim을 이용한 구현 - 2. RCA(Ripple-Carry Adder) (verilog) (0) | 2023.01.27 |
| Quartus II/ ModelSim을 이용한 구현 - 1. Multiplexer(verilog) (0) | 2023.01.26 |
| SingleCycleCpu(verilog) 설계검증 (0) | 2022.12.24 |